Abstract
In this paper, we present a novel framework for video-to-4D generation that creates high-quality dynamic 3D content from single video inputs. Direct 4D diffusion modeling is extremely challenging due to costly data construction and the high-dimensional nature of jointly representing 3D shape, appearance, and motion. We address these challenges by introducing a Direct 4DMesh-to-GS Variation Field VAE that directly encodes canonical Gaussian Splats (GS) and their temporal variations from 3D animation data without per-instance fitting, and compresses high-dimensional animations into a compact latent space. Building upon this efficient representation, we train a Gaussian Variation Field diffusion model with temporal-aware Diffusion Transformer conditioned on input videos and canonical GS. Trained on carefully-curated animatable 3D objects from the Objaverse dataset, our model demonstrates superior generation quality compared to existing methods. It also exhibits remarkable generalization to in-the-wild video inputs despite being trained exclusively on synthetic data, paving the way for generating high-quality animated 3D content.
Method
Direct 4DMesh-to-GS Variation Field VAE
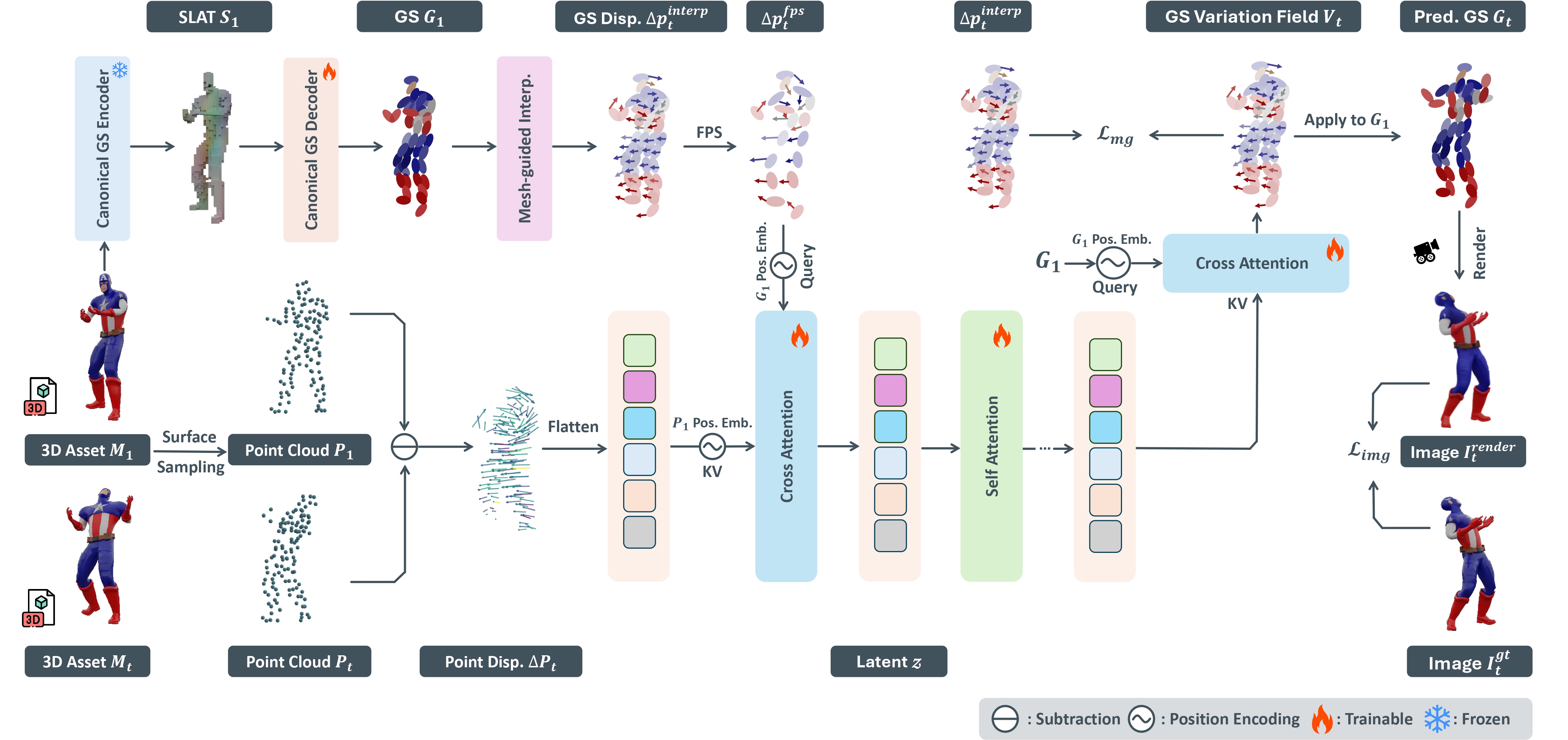
Framework of 4DMesh-to-GS Variation Field VAE. Our VAE directly encodes 3D animation data into Gaussian Variation Fields within a compact latent space, optimized through image-level reconstruction loss and the proposed mesh-guided loss.
Gaussian Variation Field Diffusion Model
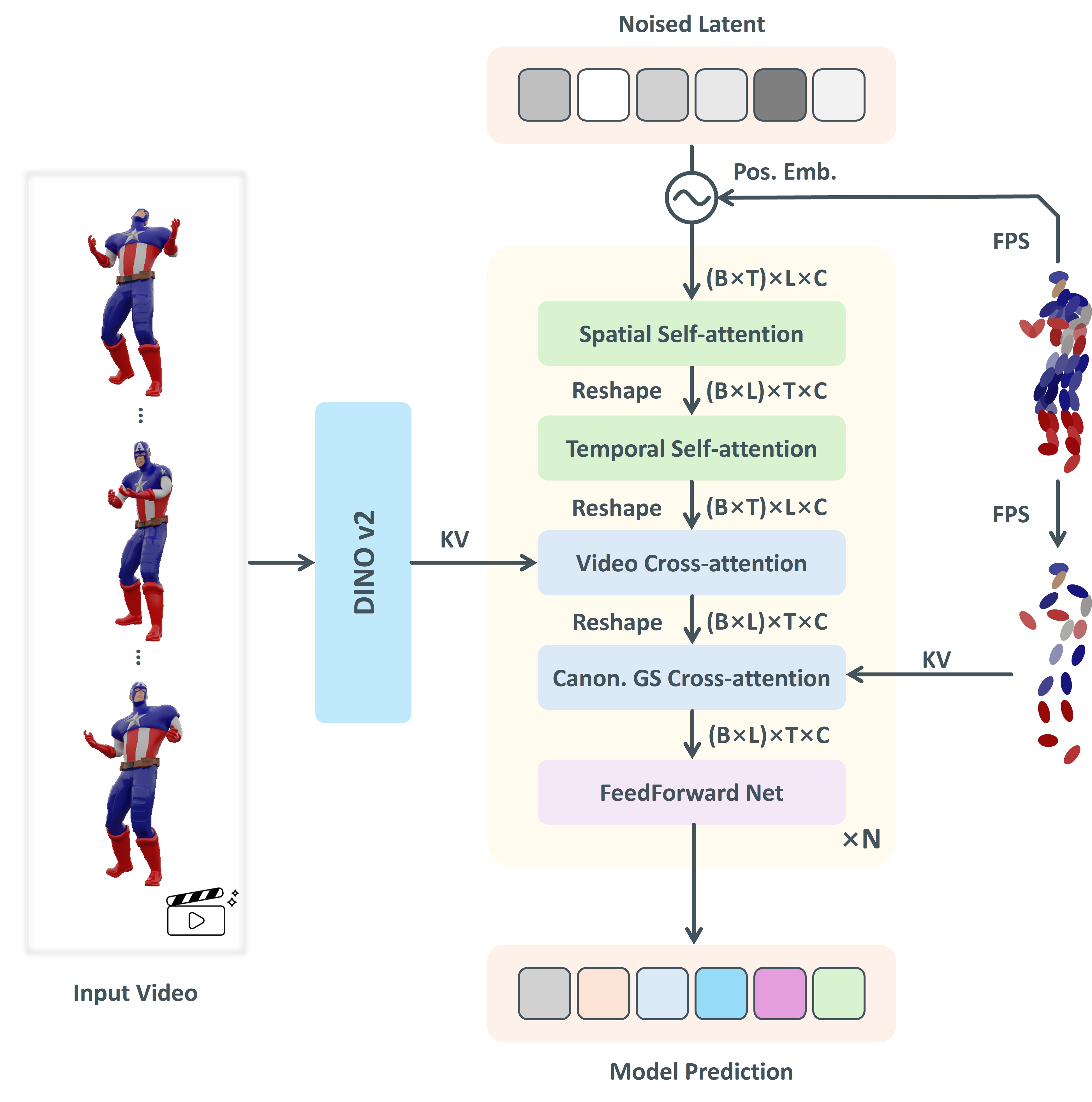
Architecture of Gaussian Variation Field diffusion model. Our model is built upon diffusion transformer, which takes noised latent as input and gradually denoises it conditioned on the video sequence and canonical GS.
In-the-wild Generation Results
More Generation Results
Animating Existing 3D Models
Visual Comparison with Other Methods
VAE Reconstruction Results
Demo Video
BibTeX
@article{zhang2025gaussian,
title={Gaussian Variation Field Diffusion for High-fidelity Video-to-4D Synthesis},
author={Zhang, Bowen and Xu, Sicheng and Wang, Chuxin and Yang, Jiaolong and Zhao, Feng and Chen, Dong and Guo, Baining},
journal={arXiv preprint arXiv:2507.23785},
year={2025}
}